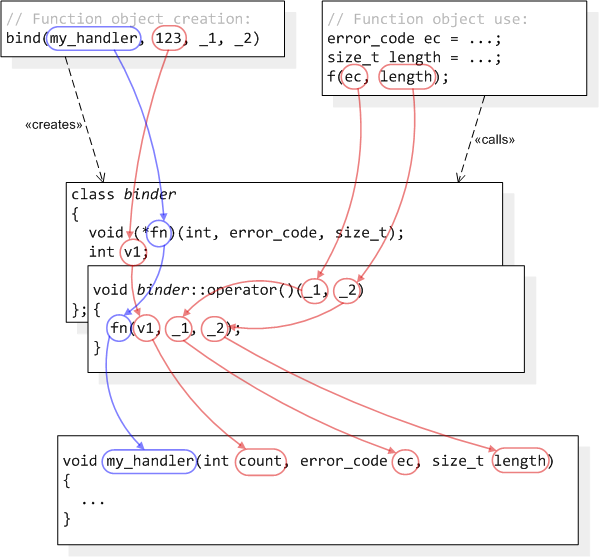
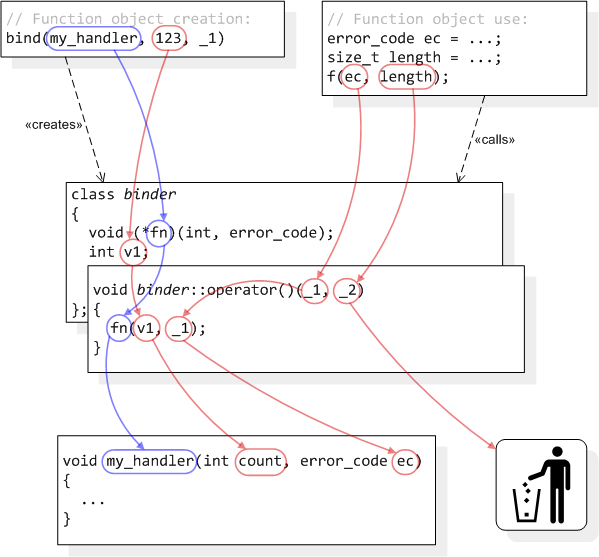
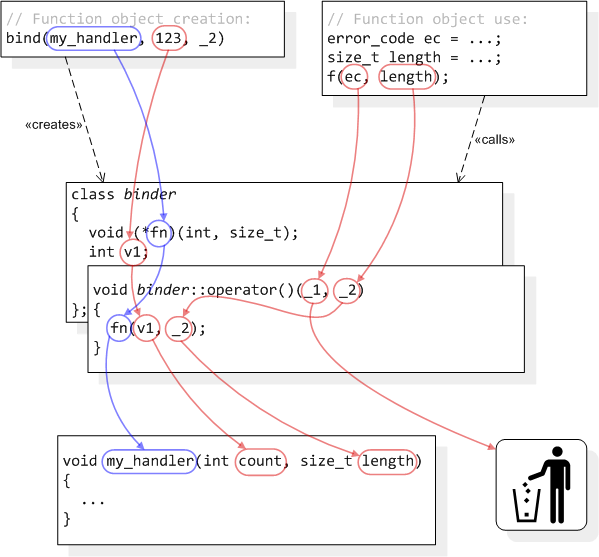
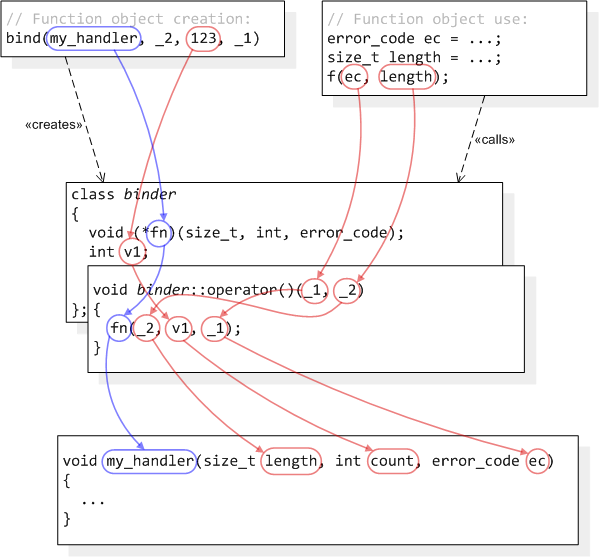
[ part 1, part 2, part 3, part 4 ]
Creating your own error conditions
User-extensibility in the <system_error> facility is not limited to error codes: error_condition permits the same customisation.
Why create custom error conditions?
To answer this question, let's revisit the distinction between error_code and error_condition:
- class error_code - represents a specific error value returned by an operation (such as a system call).
- class error_condition - something that you want to test for and, potentially, react to in your code.
This suggests some use cases for custom error conditions:
- Abstraction of OS-specific errors.
Let's say you're writing a portable wrapper around getaddrinfo(). Two interesting error conditions are the tentative "the name does not resolve at this time, try again later", and the authoritative "the name does not resolve". The getaddrinfo() function reports these errors as follows:
- On POSIX platforms, the errors are EAI_AGAIN and EAI_NONAME, respectively. The error values are in a distinct "namespace" to errno values. This means you will have to implement a new error_category to capture the errors.
- On Windows, the errors are WSAEAI_AGAIN and WSAEAI_NONAME. Although the names are similar to the POSIX errors, they share the GetLastError "namespace". Consequently, you may want to reuse std::system_category() to capture and represent getaddrinfo() errors on this platform.
To avoid discarding information, you want to preserve the original OS-specific error code while providing two error conditions (called name_not_found_try_again and name_not_found, say) that API users can test against.
- Giving context-specific meaning to generic error codes.
Most POSIX system calls use errno to report errors. Rather than define new errors for each function, the same errors are reused and you may have to look at the corresponding man page to determine the meaning. If you implement your own abstractions on top of these system calls, this context is lost to the user.
For example, say you want to implement a simple database where each entry is stored in a separate flat file. When you try to read an entry, the database calls open() to access the file. This function sets errno to ENOENT if the file does not exist.
As the database's storage mechanism is abstracted from the user, it could be surprising to ask them to test for no_such_file_or_directory. Instead, you can create your own context-specific error condition, no_such_entry, which is equivalent to ENOENT.
- Testing for a set of related errors.
As your codebase grows, you might find the same set of errors are checked again and again. Perhaps you need to respond to low system resources:
- not_enough_memory
- resource_unavailable_try_again
- too_many_files_open
- too_many_files_open_in_system
- ...
in several places, but the subsequent action differs at each point of use. This shows that there is a more general condition, "the system resources are low", that you want to test for and react to in your code.
A custom error condition, low_system_resources, can be defined so that its equivalence is based on a combination of other error conditions. This allows you to write each test as:
if (ec == low_system_resources)
...and so eliminate the repetition of individual tests.
The definition of custom error conditions is similar to the method for error_codes, as you will see in the steps below.
Step 1: define the error values
You need to create an enum for the error values, similar to std::errc:
enum class api_error
{
low_system_resources = 1,
...
name_not_found,
...
no_such_entry
};
The actual values you use are not important, but you must ensure that they are distinct and non-zero.
Step 2: define an error_category class
An error_condition object consists of both an error value and a category. To create a new category, you must derive a class from error_category:
class api_category_impl
: public std::error_category
{
public:
virtual const char* name() const;
virtual std::string message(int ev) const;
virtual bool equivalent(
const std::error_code& code,
int condition) const;
};
Step 3: give the category a human-readable name
The error_category::name() virtual function must return a string identifying the category:
const char* api_category_impl::name() const
{
return "api";
}
Step 4: convert error conditions to strings
The error_category::message() function converts an error value into a string that describes the error:
std::string api_category_impl::message(int ev) const
{
switch (ev)
{
case api_error::low_system_resources:
return "Low system resources";
...
}
}
However, depending on your use case, it may be unlikely that you'll ever call error_condition::message(). In that case, you can take a shortcut and simply write:
std::string api_category_impl::message(int ev) const
{
return "api error";
}
Step 5: implement error equivalence
The error_category::equivalent() virtual function is used to define equivalence between error codes and conditions. In fact, there are two overloads of the error_category::equivalent() function. The first:
virtual bool equivalent(int code,
const error_condition& condition) const;
is used to establish equivalence between error_codes in the current category with arbitrary error_conditions. The second overload:
virtual bool equivalent(
const error_code& code,
int condition) const;
defines equivalence between error_conditions in the current category with error_codes from any category. Since you are creating custom error conditions, it is the second overload that you must override.
If your intent is to abstract OS-specific errors, you might implement error_category::equivalent() like this:
bool api_category_impl::equivalent(
const std::error_code& code,
int condition) const
{
switch (condition)
{
...
case api_error::name_not_found:
#if defined(_WIN32)
return code == std::error_code(
WSAEAI_NONAME, system_category());
#else
return code = std::error_code(
EAI_NONAME, getaddrinfo_category());
#endif
...
default:
return false;
}
}
(Obviously getaddrinfo_category() needs to be defined somewhere too.)
The tests can be as complex as you like, and can even reuse other error_condition constants. You may want to do this if you're creating a context-specific error condition, or testing for a set of related errors:
bool api_category_impl::equivalent(
const std::error_code& code,
int condition) const
{
switch (condition)
{
case api_error::low_system_resources:
return code == std::errc::not_enough_memory
|| code == std::errc::resource_unavailable_try_again
|| code == std::errc::too_many_files_open
|| code == std::errc::too_many_files_open_in_system;
...
case api_error::no_such_entry:
return code == std::errc::no_such_file_or_directory;
default:
return false;
}
}
Step 6: uniquely identify the category
You should provide a function to return a reference to a category object:
const std::error_category& api_category();
such that it always returns a reference to the same object. As with custom error codes, you can use a global:
api_category_impl api_category_instance;
const std::error_category& api_category()
{
return api_category_instance;
}
or you can make use of C++0x's thread-safe static variables:
const std::error_category& api_category()
{
static api_category_impl instance;
return instance;
}
Step 7: construct an error_condition from the enum
The <system_error> implementation requires a function called make_error_condition() to associate an error value with a category:
std::error_condition make_error_condition(api_error e)
{
return std::error_condition(
static_cast<int>(e),
api_category());
}
For completeness, you should also provide the equivalent function for construction of an error_code. I'll leave that as an exercise for the reader.
Step 8: register for implicit conversion to error_condition
Finally, for the api_error enumerators to be usable as error_condition constants, enable the conversion constructor using the is_error_condition_enum type trait:
namespace std
{
template <>
struct is_error_condition_enum<api_error>
: public true_type {};
}
Using the error conditions
The api_error enumerators can now be used as error_condition constants, just as you may use those defined in std::errc:
std::error_code ec;
load_resource("http://some/url", ec);
if (ec == api_error::low_system_resources)
...
As I've said several times before, the original error code is retained and no information is lost. It doesn't matter whether that error code came from the operating system or from an HTTP library with its own error category. Your custom error conditions can work equally well with either.
Next, in what will probably be the final instalment, I'll discuss how to design APIs that use the <system_error> facility.